

引用
https://blog.csdn.net/javazejian/article/details/72828483#synchronized%E5%90%8C%E6%AD%A5%E4%BB%A3%E7%A0%81%E5%9D%97
https://blog.csdn.net/qq_35181209/article/details/77652278
https://www.liaoxuefeng.com/wiki/1252599548343744/1304521607217185
初探
一个任务程为进程(浏览器,word),包含的多个子任务为线程(打字,查错同时)。常用的Windows、Linux等操作系统都采用抢占式多任务,如何调度线程完全由操作系统决定,程序自己不能决定什么时候执行,执行多长时间。
线程创建与运行
public class Main {
public static void main(String[] args) {
Thread t = new MyThread();//通过扩展Thread
Thread t = new Thread(new MyRunnable());//通过实现Runnable
Thread t = new Thread(() -> {
System.out.println("start new thread!");
});//通过lombda表达式
//简单的三种创建方式
t.start(); // 启动新线程
}
}
class MyThread extends Thread {
@Override
public void run() {
System.out.println("start new thread!");
}
}
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("start new thread!");
}
}
注意,这里的MyRunnable是Runnable的实现,仍需封装在Thread中!
问题来了,我们知道,我们是通过start()来启动线程,那么start是如何调用run()方法的呢?
public synchronized void start() {
......
boolean started = false;
try {
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
/* do nothing. If start0 threw a Throwable then
it will be passed up the call stack */
}
}
}
private native void start0();
查看源码可以发现,start()方法并没有直接调用run()方法,而是在其中运行了start0()的本地方法。
根据官方解释,start0()指示操作系统(通过JVM)创建一个新的线程,并让它执行run()方法。
由此可知,直接运行run()方法并不能实现多线程。
线程状态:
- New:新创建的线程,但未执行;
- Runnable:运行中的线程,正在执行run()方法;
- Blocked:线程运行时,因某些操作被阻塞而挂起;//被动
- Waiting:线程运行时,因某些操作而在等待中;//主动
- Terminated:线程已终止,因为run()方法执行完毕。
Thread常用方法:
- setPriority()设置该线程优先级(1最低,10最高,默认5)
- Thread.sleep(long millis)当前线程睡眠(阻塞状态),单位毫秒,这是一个静态方法
- join()加入线程,当前线程阻塞,直到该线程加入后再运行(在线程a中调用b.join(),a线程等待b加入后再运行)
- interrupt()中断该线程,向目标线程发出中断请求,需线程通过isInterrupted()方法轮询并响应。与设置volatile标志位基本同理
- setDaemon()设置该线程是否为守护线程,JVM在所有线程结束后关闭除了守护现成(通常用来关闭其他线程)
新的解决方案,从线程同步开始:
同步
因为,多个线程同时运行时,线程的调度由操作系统决定,程序自身无法决定。
所以,任何一个线程都有可能在任何指令处被操作系统暂停,然后在某个时间段后继续执行。
这通常会导致读写时数据不一致问题,因为常见的i++等操作非原子操作(load,add,store)
为解决这个问题,我们可以用synchronized关键字对一个对象进行加锁
class Counter {
public static final Object lock = new Object();
public static int count = 0;
}
class AddThread extends Thread {
@Override
public void run() {
synchronized(Counter.lock) {//通过lock 对象进行加锁
Counter.count += 1;
}
}
}
//也可以这么写
public synchronized void add(int n) {//对this对象进行加锁(静态方法锁该类JVM创建的Class实例)
count += n;
}
现在问题又来了,我们知道synchronized 锁的是对象,那么它是如何实现的呢?
答案是锁对象头,一个对象通常由对象头,实例变量和填充数据组成。详见:
Synchronized
synchronized使用的锁对象是存储在Java对象头里
jvm中采用2个字来存储对象头(如果对象是数组则会分配3个字,多出来的1个字记录的是数组长度)其主要结构是由Mark Word和Class Metadata Address组成
- Mark Word(存储对象的hashCode、锁信息或分代年龄或GC标志等信息)
- Class Metadata Address(类型指针指向对象的类元数据,JVM通过这个指针确定该对象是哪个类的实例)
Mark Word在默认情况下存储着对象的HashCode、分代年龄、锁标记位等
| 锁状态 | 25bit | 4bit | 1bit是否是偏向锁 | 2bit锁标志位 |
|---|---|---|---|---|
| 无锁状态 | 对象HashCode | 对象分代年龄 | 0 | 01 |
由于对象头的信息是与对象自身定义的数据没有关系的额外存储成本,Mark Word 被设计成为一个非固定的数据结构,以便存储更多有效的数据
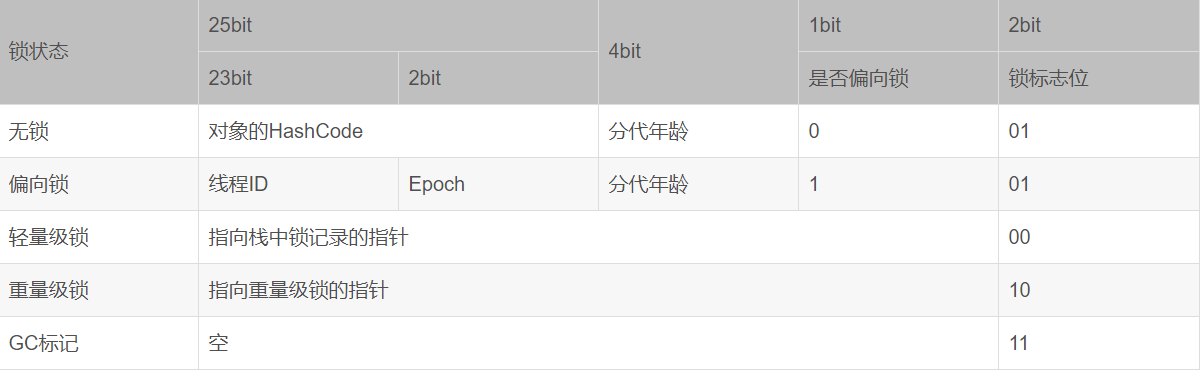
Synchronized锁的状态
锁的状态总共有四种,无锁状态、偏向锁、轻量级锁和重量级锁。锁可以从偏向锁升级到轻量级锁,再升级的重量级锁,但是锁的升级是单向的,也就是说只能从低到高升级,不会出现锁的降级。
偏向锁
为了减少同一线程获取锁(会涉及到一些CAS操作,耗时)的代价而引入偏向锁。偏向锁的核心思想是,如果一个线程获得了锁,那么锁就进入偏向模式,此时Mark Word 的结构也变为偏向锁结构,当这个线程再次请求锁时,无需再做任何同步操作,即获取锁的过程,这样就省去了大量有关锁申请的操作,从而也就提供程序的性能。
轻量级锁
轻量级锁是指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁(自旋锁是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU。),不会阻塞,提高性能。轻量级锁所适应的场景是线程交替执行同步块的场合,如果存在同一时间访问同一锁的场合,就会导致轻量级锁膨胀为重量级锁。
重量级锁
是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让其他申请的线程进入阻塞,性能降低。
锁消除
消除锁是虚拟机另外一种锁的优化,这种优化更彻底,Java虚拟机在JIT编译时(可以简单理解为当某段代码即将第一次被执行时进行编译,又称即时编译),通过对运行上下文的扫描,去除不可能存在共享资源竞争的锁,通过这种方式消除没有必要的锁,可以节省毫无意义的请求锁时间,如下StringBuffer的append是一个同步方法,但是在add方法中的StringBuffer属于一个局部变量,并且不会被其他线程所使用,因此StringBuffer不可能存在共享资源竞争的情景,JVM会自动将其锁消除。
